In this post we will learn to design, build, and deploy a RESTful API in Go using AWS Lambda. Before starting, let me give you a brief introduction about AWS Lambda.
What is AWS Lambda?
AWS Lambda is a serverless compute service that runs our code in response to events and automatically manages the underlying compute resources for us. We can use AWS Lambda to extend other AWS services with custom logic, or create our own back-end services that operate at AWS scale, performance, and security. AWS Lambda can automatically run code in response to multiple events, such as HTTP requests via Amazon API Gateway, modifications to objects in Amazon S3 buckets, table updates in Amazon DynamoDB, and state transitions in AWS Step Functions.
Lambda runs our code on high-availability compute infrastructure and performs all the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code and security patch deployment, and code monitoring and logging. All we need to do is supply the code.
Now, lets’ start with building an API that will help a local movie rental shop in managing their available movies.
API architecture
The following diagram shows how the API Gateway and Lambda fit into the API architecture:
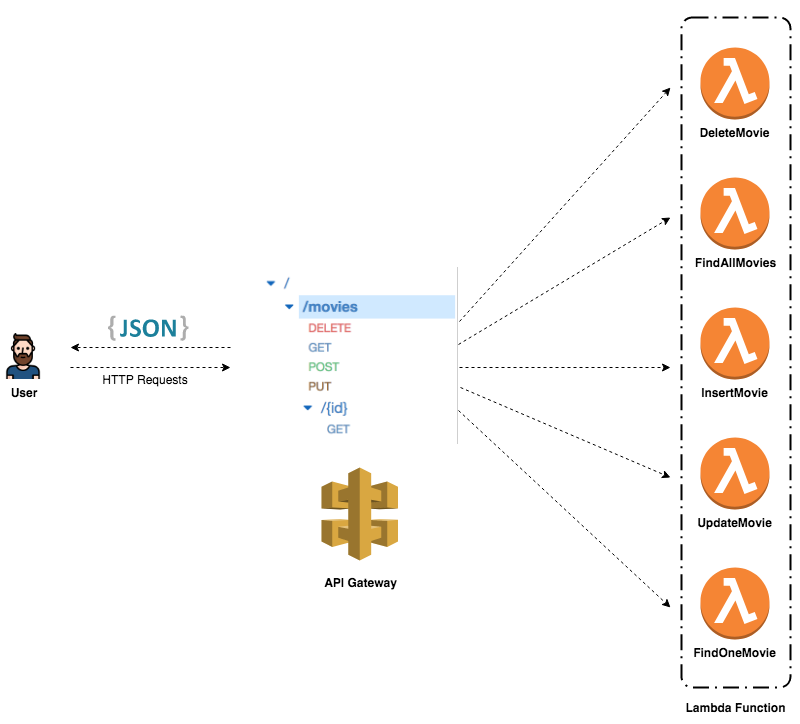
AWS Lambda empowers microservice development. That being said, each endpoint triggers a different Lambda function. These functions are independent of one another and can be written in different languages, thereby leading to scaling at function level, easier unit testing, and loose coupling.
All requests from clients first go through the API Gateway. It then routes the incoming request to the right Lambda function accordingly.
Note that a single Lambda function can Handle multiple HTTP methods (GET, POST, PUT, DELETE, and so on). It’s advisable to create multiple Lambda functions for each functionality in order to leverage the power of microservices. However, building a single Lambda function to handle multiple endpoints could be a good exercise.
Endpoints design
Now that the architecture has been defined, it’s time to go through the implementation of the functionalities described in the above diagram. Instead of hard coding the HTTP status code, you can use the net/http Go package and use a built-in status code variables such as http.StatusOK, http.StatusCreated, http.StatusBadRequest, http.StatusInternalServerError, and so on.
The GET method
The first feature to implement is listing movies. That’s where the GET method comes into play. Lets’ start with it following steps:
Step 1: Create a Lambda function that registers a findAll handler. This handler transforms a list of movies to a string and then returns this string wrapped by the APIGatewayProxyResponse variable along with a 200 HTTP status code. It also handles errors in case of conversion failure. The handler implementation is as follows:
package main
import (
"encoding/json"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
)
var movies = []struct {
ID int `json:"id"`
Name string `json:"name"`
}{
{
ID: 1,
Name: "Avengers",
},
{
ID: 2,
Name: "Ant-Man",
},
{
ID: 3,
Name: "Thor",
},
{
ID: 4,
Name: "Hulk",
}, {
ID: 5,
Name: "Doctor Strange",
},
}
func findAll() (events.APIGatewayProxyResponse, error) {
response, err := json.Marshal(movies)
if err != nil {
return events.APIGatewayProxyResponse{}, err
}
return events.APIGatewayProxyResponse{
StatusCode: 200,
Headers: map[string]string{
"Content-Type": "application/json",
},
Body: string(response),
}, nil
}
func main() {
lambda.Start(findAll)
}
Instead of hard coding the HTTP status code, you can use the net/http Go package and use a built-in status code variables such as http.StatusOK, http.StatusCreated, http.StatusBadRequest, http.StatusInternalServerError, and so on.
Step 2: Create a script file with the following content to build a Lambda function deployment package, a .zip file consisting of your code and any dependencies, as follows:
#!/bin/bash
echo "Build the binary"
GOOS=linux GOARCH=amd64 go build -o main main.go
echo "Create a ZIP file"
zip deployment.zip main
echo "Cleaning up"
rm main
Step 3: Execute the following commands to build the deployment package as .zip file:
$ chmod +x build.sh
$ ./build.sh
Step 4: Configure AWS CLI using steps mentioned here. Once configured, create an AWS role with name as FindAllMoviesRole following the steps mentioned here and verify if it is successfully created:
$ aws iam get-role --role-name FindAllMoviesRole
Above command should give the response as shown in a screenshot below:

Step 5: Next, create a new Lambda function using the AWS CLI as follows:
aws lambda create-function --function-name FindAllMovies \
--zip-file fileb://deployment.zip \
--runtime go1.x --handler main \
--role arn:aws:iam::ACCOUNT_ID:role/FindAllMoviesRole \
--region us-east-1
Once function is created it will give us the output same as shown in a screenshot below:

Step 6: Heading back to the AWS Lambda Console, you should see that the function has been created successfully:

Step 7: Create a sample event with an empty JSON, as the function doesn’t expect any argument, and click on the Test button:

You will notice in the previous screenshot that the function returns the expected output in a JSON format.
Step 8: Now that the function has been defined, you need to create a new API Gateway in order to trigger it:

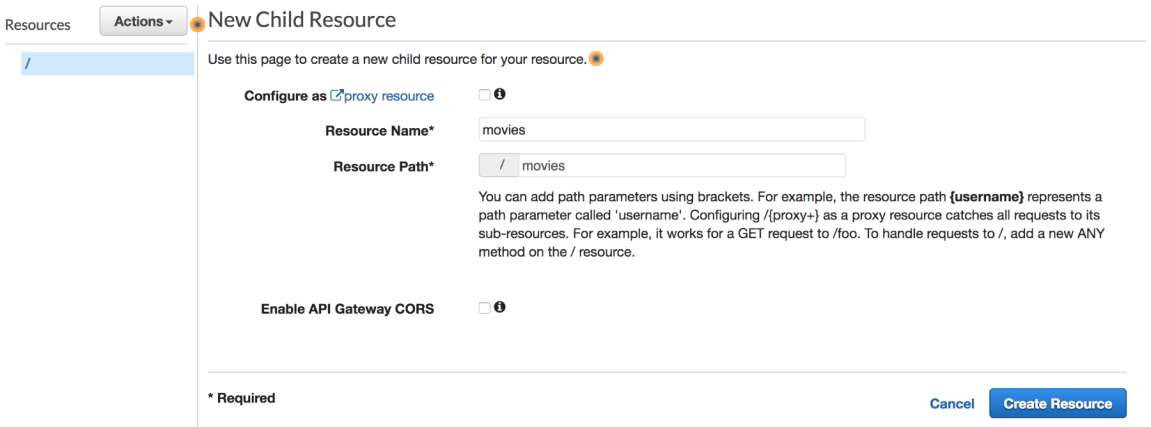
Step 9: Next, from the Actions drop-down list, select Create resource and name it movies:
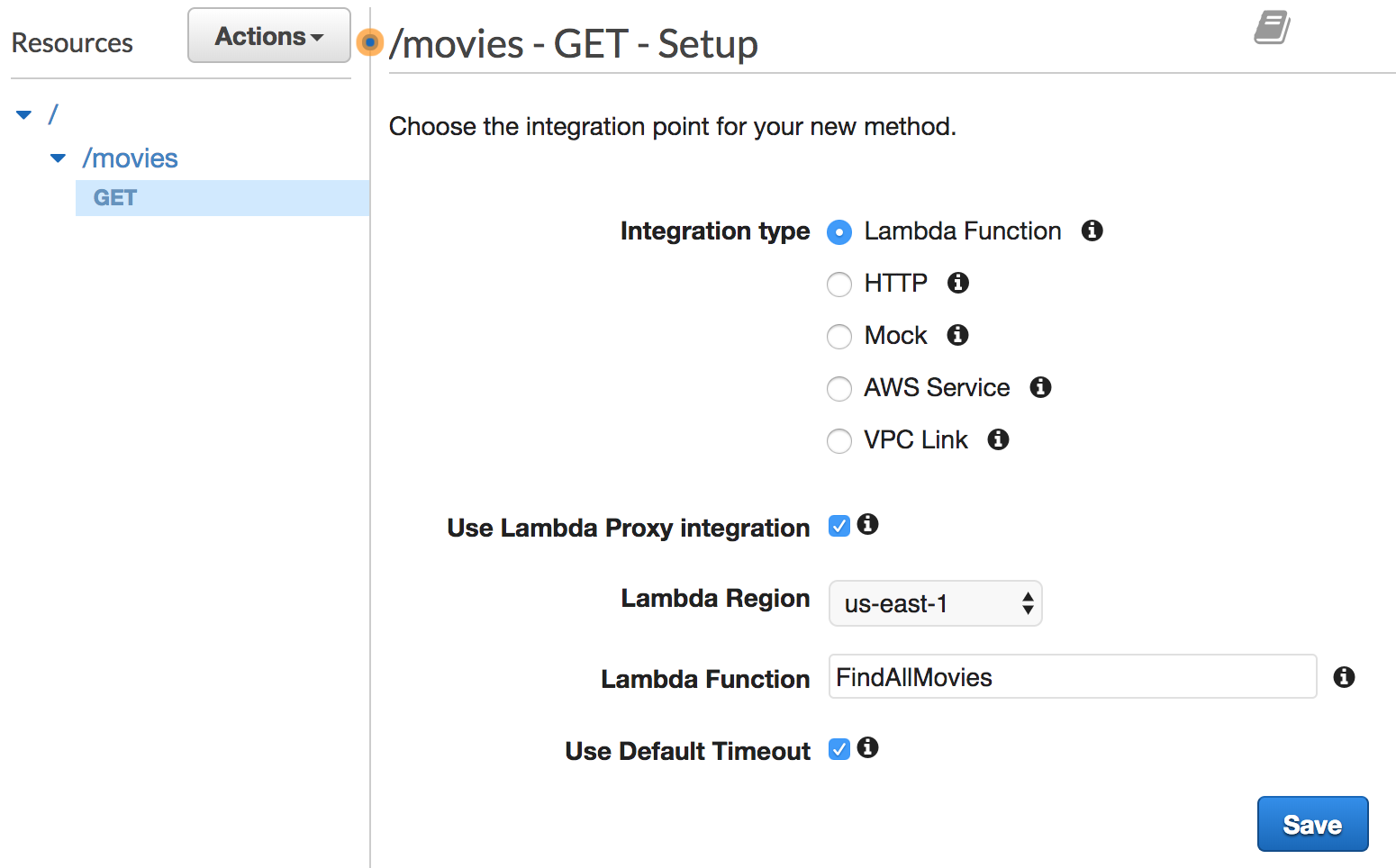
Step 10: Expose a GET method on this /movies resource by clicking on Create Method. Choose Lambda Function under the Integration type section and select the FindAllMovies function:
Step 11: To deploy the API, select Deploy API from the Actions drop-down list. You’ll be prompted to create a new deployment stage:

Step 12: Once the deployment stage is created, an invocation URL will be displayed:

Step 13: Point your browser to the URL given or use a modern REST client like Postman or Insomnia. You can go with the cURL tool as it is installed by default on almost all operating systems:
curl -sX GET https://51cxzthvma.execute-api.us-east-1.amazonaws.com/staging/movies | jq '.'
The above command will return a list of movies in a JSON format:

When calling the GET endpoint, the request will go through the API Gateway, which will trigger the findAll handler. This returns a response proxied by the API Gateway to the client in a JSON format.
Now that the findAll function has been deployed, you can implement a findOne function to search for a movie by its ID.
The GET method with parameters
The findOne handler expects the APIGatewayProxyRequest argument that contains the event input. Then, it uses the PathParameters method to get the movie ID and validate it.
If the ID provided is not a valid number, the Atoi method will return an error, and a 500 error code will be returned to the client. Otherwise, a movie will be fetched based on the index and returned to the client with a 200 OK status wrapped in APIGatewayProxyResponse:
...
func findOne(req events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) {
id, err := strconv.Atoi(req.PathParameters["id"])
if err != nil {
return events.APIGatewayProxyResponse{
StatusCode: 500,
Body: "ID must be a number",
}, nil
}
response, err := json.Marshal(movies[id-1])
if err != nil {
return events.APIGatewayProxyResponse{
StatusCode: 500,
Body: err.Error(),
}, nil
}
return events.APIGatewayProxyResponse{
StatusCode: 200,
Headers: map[string]string{
"Content-Type": "application/json",
},
Body: string(response),
}, nil
}
func main() {
lambda.Start(findOne)
}
Similar to the FindAllMovies function, create a new Lambda function for searching for a movie:
aws lambda create-function --function-name FindOneMovie \
--zip-file fileb://deployment.zip \
--runtime go1.x --handler main \
--role arn:aws:iam::ACCOUNT_ID:role/FindOneMovieRole \
--region us-east-1
Go back to API Gateway console, create a new resource, expose the GET method, and then link the resource to the FindOneMovie function. Note the use of the {id} placeholder in the path. The value of id will be made available via the APIGatewayProxyResponse object. The following screenshot depicts this:
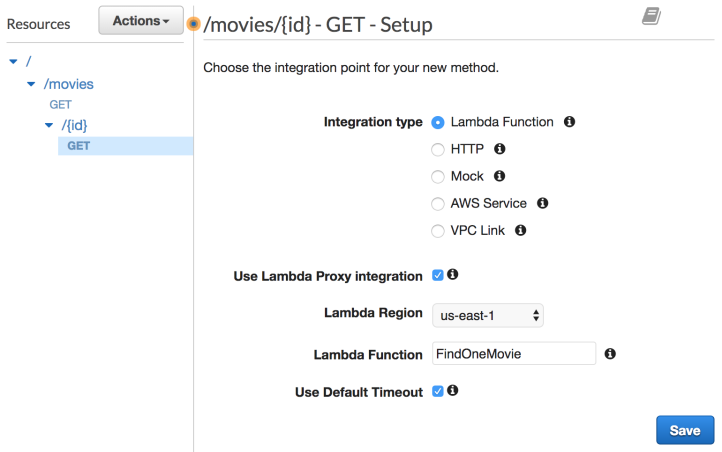
Redeploy the API and use the following cURL command to test the endpoint:
curl -sX https://51cxzthvma.execute-api.us-east-1.amazonaws.com/staging/movies/1 | jq '.'
The following JSON will be returned:

When the API URL is invoked with an ID, the movie corresponding to the ID is returned if it exists.
The POST method
Now you know how the GET method works with and without path parameters. The next step is to pass a JSON payload to a Lambda function through the API Gateway. The code is self-explanatory. It converts the request input to a movie structure, adds it to the list of movies, and returns the new list of movies in a JSON format:
package main
import (
"encoding/json"
"strconv"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
)
type Movie struct {
ID int `json:"id"`
Name string `json:"name"`
}
var movies = []Movie{
Movie{
ID: 1,
Name: "Avengers",
},
...
}
func insert(req events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) {
var movie Movie
err := json.Unmarshal([]byte(req.Body), &movie)
if err != nil {
return events.APIGatewayProxyResponse{
StatusCode: 400,
Body: "Invalid payload",
}, nil
}
movies = append(movies, movie)
response, err := json.Marshal(movies)
if err != nil {
return events.APIGatewayProxyResponse{
StatusCode: 500,
Body: err.Error(),
}, nil
}
return events.APIGatewayProxyResponse{
StatusCode: 200,
Headers: map[string]string{
"Content-Type": "application/json",
},
Body: string(response),
}, nil
}
func main() {
lambda.Start(insert)
}
Next, create a new Lambda function for InsertMovie with the following command:
aws lambda create-function --function-name InsertMovie \
--zip-file fileb://deployment.zip \
--runtime go1.x --handler main \
--role arn:aws:iam::ACCOUNT_ID:role/InsertMovieRole \
--region us-east-1
Next, create a POST method on the /movies resource and link it to the InsertMovie function:
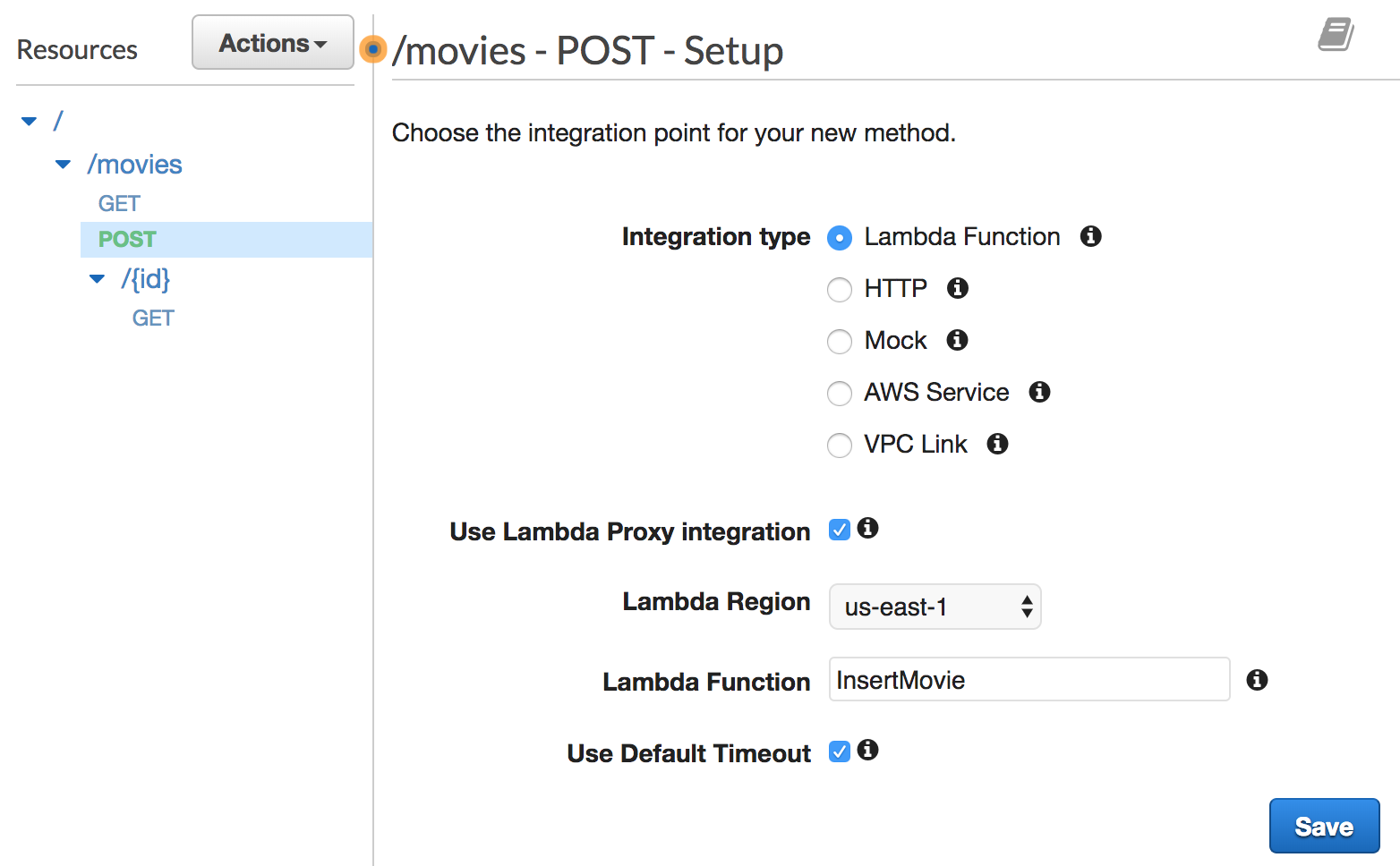
To test it out, use the following cURL command with the POST verb and the -d flag, followed by a JSON string (with the id and name attributes):
curl -sX POST -d '{"id":6, "name": "Spiderman:Homecoming"}' https://51cxzthvma.execute-api.us-east-1.amazonaws.com/staging/movies | jq '.'
The above command will return the following JSON response:

As you can see, the new movie has been inserted successfully. If you test it again, it should work as expected:
curl -sX POST -d '{"id":7, "name": "Iron man"}' https://51cxzthvma.execute-api.us-east-1.amazonaws.com/staging/movies | jq '.'
The preceding command will return the following JSON response:

As you can see, it was successful and the movie was again inserted as expected, but what if you wait few minutes and try to insert a third movie? The following command will be used to execute it again:
curl -sX POST -d '{"id":8, "name": "Captain America"}' https://51cxzthvma.execute-api.us-east-1.amazonaws.com/staging/movies | jq '.'
Once again, a new JSON response will be returned:

You will find that the movies with IDs 6 and 7 have been removed; why did this happen? It’s simple. Lambda functions are stateless.
When the InsertMovie function is invoked for the first time (first insert), AWS Lambda creates a container and deploys the function payload to the container. Then, it remains active for a few minutes before it is terminated (warm start), which explains why the second insert passed. In the third insert, the container is already terminated, and hence Lambda creates a new container (cold start) to handle the insert.
This is why the previous state is lost. The following diagram illustrates the cold/warm start issue:
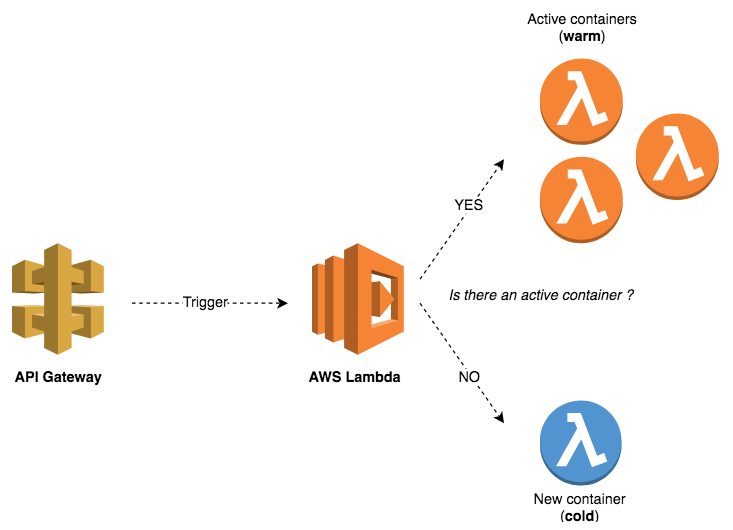
This explains why Lambda functions should be stateless and why you should not make any assumptions that the state will be preserved from one invocation to the next.
If you found this article helpful and want to learn more about Go, you can explore Hands-On Serverless Applications with Go written by Mohamed Labouardy, an AWS solution architect, and tech-reviewed by yours truly, this book will take you on a journey of learning the serverless architecture with Go and help you build highly modern, scalable, and efficient software applications.
Complete source code is hosted on github.